Factuality in generative artificial intelligence: is there an elephant in the room?

Two years ago, I wrote an article on biases and “fallback answers” in generative artificial intelligence. Back in time, I used simple examples like colors of taxis and phone booths to try to illustrate a wider problem.
It’s now time in 2025 to review this and try to measure the improvements or changes in this regard.
[Are all taxis yellow? A story of biases]
I’ll apply the same strategy by using simple verifiable elements that are linked with an unambiguous and well-defined context. Objects, colors and patterns that are obvious for us humans. A reality we can observe on a daily basis.
I’ll use different tools of generative artificial intelligence to generate images.
This experiment will talk about phone booths, newspaper kiosks, postboxes, school buses and fire hydrants.
I chose them because their versions vary depending on one factor : their location.
We also have access to many examples and images on the internet to fact check the outputs of the different models of image generation.
To achieve this task, I’ll use the latest free versions of the available cutting-edge technology:
- GPT-5 and its built-in image creator
- Microsoft Bing Image Creator using DALL-E 3 and GPT-4o
- Adobe Firefly
- Gemini 2.5 Pro
- OpenArt and the Seedream 4.0 model
In 2023, I noticed that all the taxis created by AI were yellow, the phone booths were red and British style.
The goals of those experiments are multiple:
- Determine if the context is now followed and if the link with reality has improved
- Determine if the "intelligence" can ask for more information when needed
- Observe if the tool can provide specific warnings when the model applies a fallback in case of missing data points when trying to compute an output
- Measure if the model can't provide any output at all and explain why
In 2023, I was facing a form of forced standardized outputs, taken from the American-English culture.
Most of the time without any explanation or sources that could explain this behavior. Let’s see if the situation has changed and if more accurate diversity can be generated after two years.
Biases, hallucinations have always been part of the picture when looking at artificial intelligence.
- They are present in large language models and image generation.
- They affect outputs and their acceptability at different levels.
- Providing the most plausible answer is the ground rule of AI meaning that this answer is not necessarily the closest to reality.
How do the editors communicate about the smart capacities of their products?
The big tech companies communicate that they constantly work on closing this gap.
In August 2025, Sam Altman (OpenAI’s CEO) was proud to announce that OpenAI’s latest model was so good that it could reach a PhD level in many domains.
Sam Altman: "GPT-5 is the first time that it really feels like talking to an expert in any topic, like a PhD-level expert." (7 August 2025)
[OpenAI claims GPT-5 model boosts ChatGPT to 'PhD level']
In 2024, Gemini also had problems with the concept of factuality.
[Google pauses AI-generated images of people after ethnicity criticism]
They needed to publish an apology, explanations and promises (Feb 23, 2024):
[Gemini image generation got it wrong. We'll do better.]
A double check feature is now present so the outputs are better aligned.
“Gemini tries to give factual responses to prompts — and our double-check feature helps evaluate whether there’s content across the web to substantiate Gemini’s responses — but we recommend relying on Google Search”
Adobe FireFly also faced problems so their models could match reality (Mar 13, 2024).
[Adobe Firefly repeats the same AI blunders as Google Gemini]
Their statement after the incident is the following:
"This includes extensively testing outputs for risk and to ensure they match the reality of the world we live in."
More and more people use and believe in the high level of reliability of those tools.
The latest versions are almost free, meaning that millions of people use them on a daily basis and post the outputs on the internet without necessarily tagging them as synthetic content.
Millions of images, generated by AI are now present and part of the common datasource and knowledge of humanity.
We can’t take them back.
Can we practically verify the promises about factual responses?
The task is not easy but finding examples and trying to challenge those tools is the only way to obtain an answer as objective as possible.
Measuring the progress through time using consistency is one way to have an idea.
The reproducibility is not an obvious concept in generative artificial intelligence.
Those models are versatile, it might be complicated to extract consistent patterns : we'll see.
The phone booth case: a classic and stable one
This example was already present in my 2023's experiment. I decided to give it one more shot by adding more context.
For example by exploring different places in the world and making the AI generate images applied to specific locations.
Phone booths are not really present anymore. I decided to frame the prompt by targeting the 1980's.
Many images are available on the internet for many countries.
I decided to create prompts in French at first.
There are no traps in the prompts, no play on words.
A clear notion of time and space and sometimes an iconic building or place so the artificial intelligence can't be "fooled".
The context itself should be enough to determine the style of the kiosk and the phone booth.
They are plain and simple but they should give enough context to a PhD-level tool.
The prompt in French looks like that:
"Crée moi une vue de Paris avec la tour eiffel en fond, une avenue typique, un kiosque à journaux et une cabine téléphonique dans les années 1980"
It means in English:
"Create a view of Paris with the Eiffel Tower in the background, a newspaper kiosk and a phone booth in the 1980s".
I asked GPT-5 first and changed the location and the iconic building or monument in the prompt.
Here are the results for Paris, Berlin, Brussels, Lisbon, Cairo and New-York:






We’re facing here a double “standardization” process and result for the phone booths:
- It's very likely possible to find the specific version or versions of a phone booth in public images for Paris, Berlin, Brussels and New-York. The presence, on the image, of the "British fallback" in this case is odd and we can argue that the so-called "intelligence" was not this smart or accurate.
- For Cairo, I'm quite sure that the reference does not exist, this creation does come from the fallback directly because not providing an answer is not an option for the tool. I'm also quite sure that it did not look like this at all.
For both cases, GPT-5 never warned me that it was applying a "default model" or that the data was simply missing.
There's clearly a gap between those creations and reality. The promise of factuality is not fulfilled.
But, if we trust Sam Altman’s claim, it is how a phone booth looked like in those places in the 1980s.
I pushed the experiment with GPT-5 by adding three more locations: Venice, Rio and Barcelona. During those sessions, GPT-5 asked me for more details, specifically regarding the phone booth.
As I did not want to pick the style myself but let the artificial intelligence do its job, my answer was: “Provide a realistic picture and a style for the phone booth aligned with the context
Here are the results:



At least the phone booths were not British styled.
Let’s have a closer look at the newspaper kiosks.
All of them have a strong Paris style design which is an oddity.
The Italian one is close enough to reality to be mistaken.
I tried a new round of tests in Bing Microsoft Image Creator (Dall-e-3 engine) by prompting in English this time.
“Create a realistic Paris view with the Eiffel Tower in the background, a newspaper kiosk and a phone booth in the 1980s”.

"Create a realistic Cairo view with the site of Gizeh in the background, a newspaper kiosk and a phone booth in the 1980s".

"Create a realistic Liberty Island view with the statue of Liberty in the background, a newspaper kiosk and a phone booth in the 1980s".

Dall-e-3 generates 4 images for each prompt.
The images are way more messy and hallucinated than GPT-5 but without any surprise our London Booths are overrepresented in the outputs : 75% of them.
Mailboxes on the streets: what do they look like in different countries?
In our neighborhood, we can see them everyday and it’s what we see:
- In the United Kingdom, they are red and round on the ground.
- In France they are yellow square-ish and most of the time hanging on walls
- In Sweden they are yellow or blue on a grey foot. Square-ish.
- In Spain they are round and yellow.
- In Ireland they are round and green.
There are pictures all over the internet.
Let's ask Gemini 2.5 Pro in plain English something really simple:
"Create a realistic picture of a typical mailbox on a street of Paris, France in 2025".

And Microsoft Bing Image creator for the same prompt:

Notes:
- Dall-e-3 does not really understand the concept of realistic. It did trigger something.
- Use of specficic terms: I tried with the term "mailbox" and the term "postbox" and the results are equivalently false.
Two more tries try with Microsoft Bing Image creator by changing the location: Cork and Stockholm.
“Create a realistic picture of a typical mailbox on a street of Cork, Ireland in 2025”.

“Create a realistic picture of a typical mailbox on a street of Stockholm, Sweden in 2025”.

Microsoft has apparently delegated the generative AI to a disfunctionnal model and gave it synthetic substances :-)
At this point Bing image creator does not help much.
Now, give it a try with OpenArt (Seedream 4.0) and Paris again
“Create a realistic picture of a typical mailbox on a street of Paris, France in 2025”.
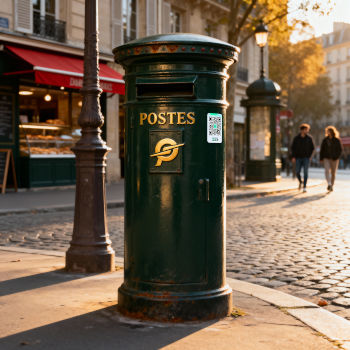
Not the answer we expect and there’s a bonus equipment for this one: a QR code has appeared !
Adobe FireFly with the same prompt
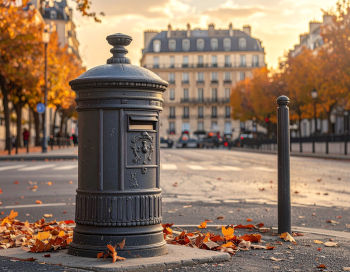
Nothing really close to reality despite a clear context given to the AI.
As GPT-5 is advertised as the best model of the market I asked for a family picture.
An image containing specific variants of mailboxes on the street by specifically pointing out the fact that they should be different.
"I would like to see public postboxes on the streets of different countries to compare and recognize them. Can you generate a realistic actual picture with the following versions so I could recognize them : - a postbox from United Kingdom in 2025- a postbox from France in 2025
- a postbox from Spain in 2025
- a postbox from Sweden in 2025
- a postbox from USA in 2025"

The UK and USA images are spot on. Those are likely the most represented in the training data.
The French model is almost correct.
The Spanish and Swedish ones are not correct at all.
What about school buses though?
“Create a realistic picture of a school bus on a countryside road of France in 2025”
For Gemini 2.5 Pro first

For Adobe Firefly

Both of them have the same answer: Yellow it is. The American version.
I prompted it in French a few months ago and the standard bus color and shape almost all over the world is the American one.
One more time in GPT-5 I tried to create a new family picture.
“I would like to see public school buses on the roads of different countries to compare and recognize them. Can you generate a realistic actual picture with the following versions so I could recognize them :
- a school bus from USA in 2025
- a school bus from United Kingdom in 2025
- a school bus from France in 2025
- a school bus from Spain in 2025
- a school bus from Sweden in 2025”

The models are different but they are all yellow.
We also notice that it’s complicated to see where the steering wheel is placed in the English bus.
But we don’t see any door on the left hand side of the bus.
The entry door seems to be like the other buses on the right hand side which is contextually wrong if we apply the well known and documented traffic rules of the United Kingdom.
One last for the road : fire hydrants
Fire hydrants are like phone booths and postboxes and school buses, there are specific versions out there.
And they are documented as well.
[https://en.wikipedia.org/wiki/Fire_hydrant]
Let's ask Gemini 2.5 Pro for the american version of it one
"Create a realistic picture of a fire hydrant on a street of New-York in 2025"

Well done. It’s correct and not really a surprise statistically speaking.
Let's ask now for the french version of hydrant.
"Create a realistic picture of a fire hydrant on a street of Paris, France in 2025"

The same shape but in green.
Not even close to reality, you can check on the internet by yourself and see if you can find a reliable answer faster than an AI that took at least 2 minutes to generate it.
Let’s try by prompting and asking for the french version of the equipment in French language to see if we can trigger more context from the question’s language as well.
“Créé une image réaliste d’une borne incendie dans les rues de Paris, France en 2025”

And Adobe Firefly for the same prompt in French?

Well, it does provide the american version of it : red.
Finally I asked GPT-5 to provide me a group picture.
"I would like to see fire hydrants on the streets of different countries to compare and recognize them.
Can you generate a realistic actual picture with the following versions so I could recognize them:
- a fire hydrant from USA on a street of New-York in 2025
- a fire hydrant from France on a street of Paris in 2025
- a fire hydrant from Sweden on a street of Stockholm in 2025"

The shapes are all the same or derived from a standard model, only the color does change.
This is not correct. You couldn’t recognize them on the streets as I asked.
AI is often advertised as the perfect replacement for humans : equivalent skills, cheaper and working faster.
Here’s another prediction or vision from Sam Altman:
https://www.creativeboom.com/news/its-official-ai-is-coming-for-your-graphic-design-job/
“Soon, AI tools will do what only very talented humans can do today”
Both everything and nothing really concrete is in this “soon”.
But the processes and interactions are not the same.
If I take the example of the Cairo photo including a phone booth and the newspaper kiosk, working with a human would be a lot different.
The exact same mission for a designer would lead to a first step of research.
This person would likely come back with more questions than answers.
The uncertainty regarding the result is directly driven by the sources and knowledge we could or could not gather.
This part of the job should be transparent and visible as an obvious communication stream.
This entire part has disappeared when dealing with AI.
On the specific topic of quality and productivity, this article from Harvard Business Review provides a detailed study and good links to read.
AI-Generated “Workslop” Is Destroying Productivity
https://hbr.org/2025/09/ai-generated-workslop-is-destroying-productivity
“Employees are using AI tools to create low-effort, passable looking work that ends up creating more work for their coworkers."
“AI generated work content that masquerades as good work, but lacks the substance to meaningfully advance a given task”
This article also introduces the new term “workslop”. It’s a really interesting concept that describes well the situation we’re in.
What about the world of IT development?
“Meta CEO Mark Zuckerberg has said that the company’s artificial intelligence is no worse than mid-level programmers."
https://dev.ua/en/news/tsukerberh-liubyt-ai-ta-dzho-rohana-1736781100
As an experienced developer, I can’t agree with this one.
I use AI in my daily job (Copilot, Sana) and the results are varying from acceptable to unusable depending on the topic.
It works for well documented boilerplates. It does not work when dealing with contextualized business logic.
At some point, the prompt needs so many details that it’s easier to write the final code and unit tests associated with it myself.
This statement is far too exaggerated. Mark Zuckerberg plays the hype and drives it recklessly.
Let’s go back to our main train of thoughts.
What if the problem is limited to phone booths, mailboxes, fire hydrants and not as broad as we could fear?
This is a good question.
I don’t have all the skills in the world to challenge every output and explore every case.
Hopefully, other people also write about the limits they see.
Gary Marcus: A story of horses, astronauts and bikes.
“Three years ago Google promised us “deep language understanding” for image generation. I don’t think we are there yet."
https://garymarcus.substack.com/p/image-generation-still-crazy-after
Biased images created in the field of medicine (2025 Jul 19)
https://pmc.ncbi.nlm.nih.gov/articles/PMC12276360/
“Yet, recent research has shown that AI algorithms in general, as well as generative AI algorithms in particular, are susceptible to biases based on sex and gender as well as race and ethnicity. Especially females and people of color were shown to be under-represented in established training datasets”
“Across the 29 diseases, the representation of disease-specific demographic characteristics in the patient images was often inaccurate for all four text-to-image generators”
“In addition, we observed an over-representation of White and normal weight individuals."
Another medicine story here and anatomy with muscles that don’t exist
https://bsky.app/profile/clairezagorski.bsky.social/post/3m2wo43l25s2r
Despite all promises from big tech companies, we can collect feedback in many domains that generative AI does not seem as accurate as advertised and probably a bit dangerous in some cases if we don’t pay enough attention.
And it’s not really a complete surprise if we read a bit more the scientific literature available in the domain.
What can we find if we dig deeper into technical and scientific details?
First a quick peak in how dall-e-3 works or was working 2023
https://medium.com/@surabhimali/understanding-dall-e-how-diffusion-models-transform-text-into-images-part-4-aiseries-de84e7ad7584
“It begins by encoding the text into a latent space representation, capturing the semantic essence of the description."
“This extensive training equips DALL-E with the ability to understand the statistical relationships between text and images."
We talk about statistical relationships here.
In this paper from OpenAI regarding Dall-e-3
https://cdn.openai.com/papers/dall-e-3.pdf
In the section “3.5 Practical usage of highly descriptive captions”:
“Generative models are known to produce poor results when sampled out of their training distribution”
In the section “4.2 Human Evaluations - Page 12” in order to validate and fact check the models’ proposals:
“Choose which image contains more coherent objects. A “coherent” object is one that
could plausibly exist. Look carefully at body parts, faces and pose of humans, placement of objects,
and text in the scene to make your judgement. Hint: count instances of incoherence for each image
and choose the image with less problems."
And more recently how GPT-4o Image generation is presented officialy
https://openai.com/index/introducing-4o-image-generation/
“GPT‑4o image generation excels at accurately rendering text, precisely following prompts, and leveraging 4o’s inherent knowledge base and chat context”
“the resulting model has surprising visual fluency, capable of generating images that are useful, consistent, and context-aware."
“Context-aware” is the keyword here.
And in the system card
https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
“We aim for the model to fill in those details in ways that reflect relevant context, including reflecting a relevant range of possibilities rather than defaulting exclusively to the most common demographics."
It’s interesting here that they use the words “defaulting exclusively to the most common demographics”.
It means that this strategy does exist somewhere in the chain of decision.
“Defaulting” seems to be an explanation for the outputs I obtained in my experiments.
And this one to finish
https://www.computerworld.com/article/4059383/openai-admits-ai-hallucinations-are-mathematically-inevitable-not-just-engineering-flaws.html
“The study, published on September 4 and led by OpenAI researchers […] explaining why AI systems must generate plausible but false information even when trained on perfect data”
The underlying scientific paper here from OpenAI themselves
https://arxiv.org/pdf/2509.04664
“Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such “hallucinations” persist even in state-of-the-art systems and undermine trust”
After reading this we understand better why those flaws do exist and that is it complicated even for “state-the-art” systems to fix that.
Can generative artificial intelligence really understand our world so it can provide safe and sound outputs?
According to Yann LeCun, Chief AI Scientist for Facebook AI Research (FAIR), it’s not a question of data anymore.
We reached a limit in the evolution of LLMs.
A fundamental capacity is missing: “Understanding the physical world”
https://www.university-365.com/post/meta-ai-vision-yann-lecun-insights-about-future-beyonds-llm
Gemini and GPT-5 are sold to be multimodal, there’s an LLM in the loop to help create images.
Can we use those tools safely without being a specialist and be aware of those limitations?
Without reading a ton of scientific literature or even being able to identify it? Well, a clear instruction manual and documented limits would be easier but …
Today, those limitations are not documented so everyone could read them.
Gemini or GPT are not delivered with such a detailed instruction manual or domain specific guidelines.
There’s no catalogue available to flag the zones or domains of uncertainty.
In those conditions and as a normal user, you don’t know when you enter the danger zone specifically if the model can’t provide you an explanation to its answer or a level of confidence.
Some of us can enter without knowing because it’s meant to be simple to use.
The other ones do react naively to synthetic reality and believe that illustrations are enough realistic (plausible) to be factual.
On social networks. sharing photos of nature in Facebook groups with birds that don’t exist.
Facebook became a creepy place.
https://www.npr.org/2024/05/14/1251072726/ai-spam-images-facebook-linkedin-threads-meta
“Facebook’s AI-Generated Spam Problem Is Worse Than You Realize”
https://www.rollingstone.com/culture/culture-features/facebook-ai-generated-slop-1235095088/
Real estate start selling houses that don’t exist or at least using synthetic photos
https://futurism.com/artificial-intelligence/listing-rental-house-mangled-ai
Students are looking for books that don’t exist
https://apnews.com/article/fake-book-list-ai-newspaper-summer-reading-fcdf454a5b467dad3adfed6ca1a224d2
https://www.404media.co/librarians-are-being-asked-to-find-ai-hallucinated-books/
The question of usage of generative artificial intelligence is a question of trust and awareness.
Being aware that the technology is flawed by design so you need to double check every output you’re about to post publicly. This is a collective responsibility to do so.
The French government briefly published a video to commemorate the Liberation of Paris in 1944.
Instead of using images for archives, an AI tool helped to create a video.
The video was unpublished rapidly because it was historically inaccurate:
- A German soldier was celebrating with the crowd
- A Japanese flag was visible out of a window


The problem can also happen in another layer of factuality : impersonation.
OpenAI pauses Sora video generations of Martin Luther King Jr.
https://techcrunch.com/2025/10/16/openai-pauses-sora-video-generations-of-martin-luther-king-jr/
“OpenAI announced Thursday it paused the ability for users to generate videos resembling the late civil rights activist Martin Luther King Jr. using its AI video model, Sora. The company says it’s adding this safeguard at the request of Dr. King’s estate after some Sora users generated “disrespectful depictions” of his image."
Is it not important to be factual anymore or grounded in reality?
The race of generative AI is not about being factual or fair : it’s about conquering markets, killing your opponents by being cheaper and faster.
The market share seems to be the driver and the cost for us is to create, at scale, a synthetic reality and artefacts on the internet that will diverge more and more from facts.
We’re already down this path and the marketing messages are here to downplay a situation that is worrying.
Wikipedia’s future is at stake
https://www.404media.co/wikipedia-says-ai-is-causing-a-dangerous-decline-in-human-visitors/
“Ironically, while generative AI and search engines are causing a decline in direct traffic to Wikipedia, its data is more valuable to them than ever."
The same questions as in 2022 are on the table and “we” look away.
https://www.longshot.ai/blog/importance-of-checking-ai-content
The consequence of that is the place of trust in our society.
By saturating the space with inaccurate synthetic reality we accept to replace our sources of truth with synthetic outputs.
And we don’t need a big amount of it so we kill the original idea of the internet which was at the beginning a place to share knowledge and ideas.
I don’t have any solution but one thought after those hours of research and documentation is that we humans must be more vigilant than ever. More informed than ever. More technically capable than ever.
Artificial intelligence is not this intelligent and we should not accept this easily the future written in the stone by tech marketers.
Between being transparent and honest and battling with billions against their concurrent to secure their market share (if not monopoly): they have chosen.
What are we doing now?
I’m a tech enthusiast and this article can sound a little worrying and pessimistic.
There are cases and problems where those tools are already useful and can provide helpful inputs and solutions.
We just need to find them in the constant noise between two trendy useless “must test, must have” features.
Does “starter pack” ring a bell? Was the wave of “emotion” really necessary?
Let’s focus.
We can do better with technology if we start from the actual problems and not from the projected hypothetic generalizable solutions.
Did you know that firefighters could use the help of technology to accomplish their duty?
It’s called “AlertCalifornia” and was launched in May 2023.
Clear and vital purposes: detect early, act fast, save lives.
An article here:
https://www.firehouse.com/technology/artificial-intelligence/news/55317973/new-ai-cameras-finding-ca-wildfires-before-humans
Their website:
https://alertcalifornia.org/technology/
“The value of this public-private partnership is the development of AI to aid firefighters, mitigate watchstander fatigue, reduce false positives, and confirm fire incidents in the incipient phase."
Thanks for reading.
Don’t hesitate to contact me or follow me on Blue Sky.
https://bsky.app/profile/kindrobot.bsky.social
Published: 2025-10-18 07:00:00 +0000 UTC